Scoris turėjo vieną didelį, nors ir nelabai pastebimą trūkumą. Duomenys būdavo atnaujinami tik kartą per mėnesį, todėl dalis duomenų būdavo mėnesio ar net dviejų senumo. Nuo šiandien Scoris svetainėjė – naujausi įmonių duomenys visada. Duomenys atnaujinami automatiškai, kiekvieną dieną.
Kodėl duomenys būdavo atnaujinami tik kartą į mėnesį?
Manau dažna startup’ų problema, kad pradedant veiklą nėra noro daryti delių investicijų į infrastruktūrą, nes tai kainuoja nemažai laiko ir pinigų. Pradedant veiklą svarbu MVP PoC (minimum viable product, proof of concept), t.y. veikiantis produktas su minimaliom pastangom ir resursais. Kai tokį produktą įmonė turi, ji gali eiti žvalgyti rinką. Žiūrėti ar produktas pasiteisins ir jeigu pasiteisins, tuomet modernizuoti infrastruktūrą. Čia idelus variantas.
Dažnas realus variantas – pradedi nuo MVP PoC ir statai ant jo toliau. Pradeda lūžti – paremi pagaliais ir judi toliau. Po metų, infrastruktūros modernizavimas tampa didžiuliu darbu, nes PoC per daug išsiplėtė.
Panašiai buvo ir su Scoris. Sulipdėm duomenų modelį ant Knime. Geras įrankis, bet neskirtas duomenų bazės darbams. Pradžioje prasisukdavo rankom per maždaug pusvalandį. Bet Scoris augo ir Knime plėtėsi. Šalia Knime atsirado Python skriptai, MS Excel PowerQuery. Kelios tarpinės duomenų bazės.
Pabaigoje atnaujinimo procesas užtrukdavo ~3 valandas. O pats Knime workflow atrodė taip:
Visas šis vorantinklis tiesiog nebuvo pritaikytas automatizavimui ir optimaliam veikimui. Tai yra sumonstrėjęs PoC ir tai yra priežastis, kodėl kasdieninis duomenų atnaujinimas nebuvo realus.
Naujos duomenų infratruktūros paieškos
Kad reikia perdaryti duomenų infrastruktūrą, buvo aišku jau seniai, bet jau seniai PoC buvo sumonstrėjęs tiek, kad toks darbas buvo labai didelis. Kiek didelis? Maždaug tiek:
- Virš 100 duomenų šaltinių
- Turbūt visi įmanomi failų formatai (csv, xlsx, json, zip).
- Nuolat besikeičiantos duomenų struktūros
- ~40 Gb raw duomenų
Žinojau, kad perdarymas neišvengiamas todėl pradėjau ieškoti tinkamiausio sprendimo. Buvo reikalingi keli komponentai:
- Duomenų parsiuntimas
- RAW duomenų įrašymas į tarpinę DB
- Duomenų paruošimas, modeliavimas
- Galutinių rezultatų paskelbimas
3-čias punktas buvo aišku, kad naudosiu SQL, kad kokios technologijos bebūtų (Postgres, MySQL, MS SQL etc.). 4-tas punktas irgi buvo aiškus, kadangi svetainė pakurta ant MySQL duomenų bazės ir galutinio rezultato daug keisti nenorėjau, nes viskas veikė gan gerai. Didžiausias galvos skausmas buvo 1-2 punktai.
Nesėkmingi bandymai
Pradėjau nuo keboola. Nemokama versija žadėjo 250 Gb duomenų ir ~1h compute-laiko. Parsiųsti duomenis ir įrašyti į tarpinę DB pats susitvarkydavau per valandą, tai maniau, kad galingi debesies kompiuteriai susitvarkys ir greičiau. Klydau – užkrovus vos 3-4 failus jau išnaudojau 120min compute laiko, o buvo likę dar >90 failai. Teko atsisakyti sprendimo, nes mokamo sprendimo kaina būtų per didelė.
Antras bandymas buvo Airbyte. Yra nemokama versija on-prem diegimui. Taigi išsinuomojau vidutinį VPS (64Gb RAM, 8 branduoliai) įdiegiau Airbyte ir pradėjau darbus. Nemokamas Airbyte labai prastai optimizuotas. Užkrauti keletos Gb failą į duomenų bazę reikalavo 100% serverio resursų (CPU ir RAM), ir pasiekus resursų limitą veikimas labai sulėtėdavo. Teko atsisakyti sprendimo, nes veikimas per lėtas ir/ar reikia per daug resursų paprastam darbui atlikti.
Trečias bandymas buvo do-it-yourself (DIY) naudojant Open-Source sprendimus. Python skriptas parsiųsti duomenim ir įrašyti į Postgres duomenų bazę. Aiflow orkestravimui. Šis sprendimas maniau ir bus galutinis. Veikė greitai, nekainavo. Duomenų transformavimui maniau naudosiu DBT. Problema buvo, kad norint viską sukontroliuoti kodas pradėjo darytis ilgas ir sunkus. To nedarant veikimas nebuvo stabilus. Vienam žmogui pasirodė per didelis darbas.
Kitais tikslais teko pasimokinti dviejų technologijų Azure cloud ir MS SQL server (SSIS). Pradėjau paraleliai bandyti padaryti ant šių dviejų technologijų, kad pažiūrėčiau gal kas nors tiks ir patiks. Abi technologijas buvo sunku prisijaukinti, per daug konfigūravimo, sudėtingai skaitomi klaidų pranešimai, bet su laiku lengvėjo. Ir abi technologijos gan patiko. Nusprendžiau, kad bus kur nors iš šių technologijų. Galiausiai po kiek laiko atkrito Azure, nes:
- Pritrūko kontrolės. Dažnai workardound’inti ribojimus reikėjo naudoti python skriptus ant Spark cluster’io, kas nebuvo paprasta ir reikalavo nemažai resursų.
- Kaina pradėjo pūstis. Mokama už panaudotus resursus, bet nepadarius nei 10% kaina jau buvo ~5 EUR/dienai. Padarius viską, manau nebūtų pigus sprendimas.
Taigi atkritus visiem variantams liko MS SQL serveris su SSIS. Kitiems tikslams jau turėjau parodų namų serverį kuris gyvas 24/7 (ant UPS su failover internetu), pavyko nebrangiai nusipirkti MS SQL 2019 server licenciją ir pradėjau darbus.
MS SQL 2019 server paremta duomenų architektūra 2023 metais??!!
Neteko matyti, kad nors 2023 metais rekomenduotų tokią duomenų architektūrą. Tiek MS SQL server, tiek SSIS atrodo gan legacy technologijos, bet išbandžiau ne vieną „modernų” variantą ir šis „nemodernus” tiko labiausiai.
- Didžiausias privalumas – greitis ir lankstumas. 40-60GB duomenų apdoroti per pusvalandį manau geras benchmark’as 🙂 Sistema veikia gan stabiliai.
- Didžiausias trūkumas – sistema gan sena ir nėra ir labai protinga, todėl viską reikia iki smulkmenų sukonfiguruoti ir aprašyti. Kitas trūkumas – teisingas access-rights valdymas Windows/SQL serveryje.
Bendras paveiklas atrodo štai taip:
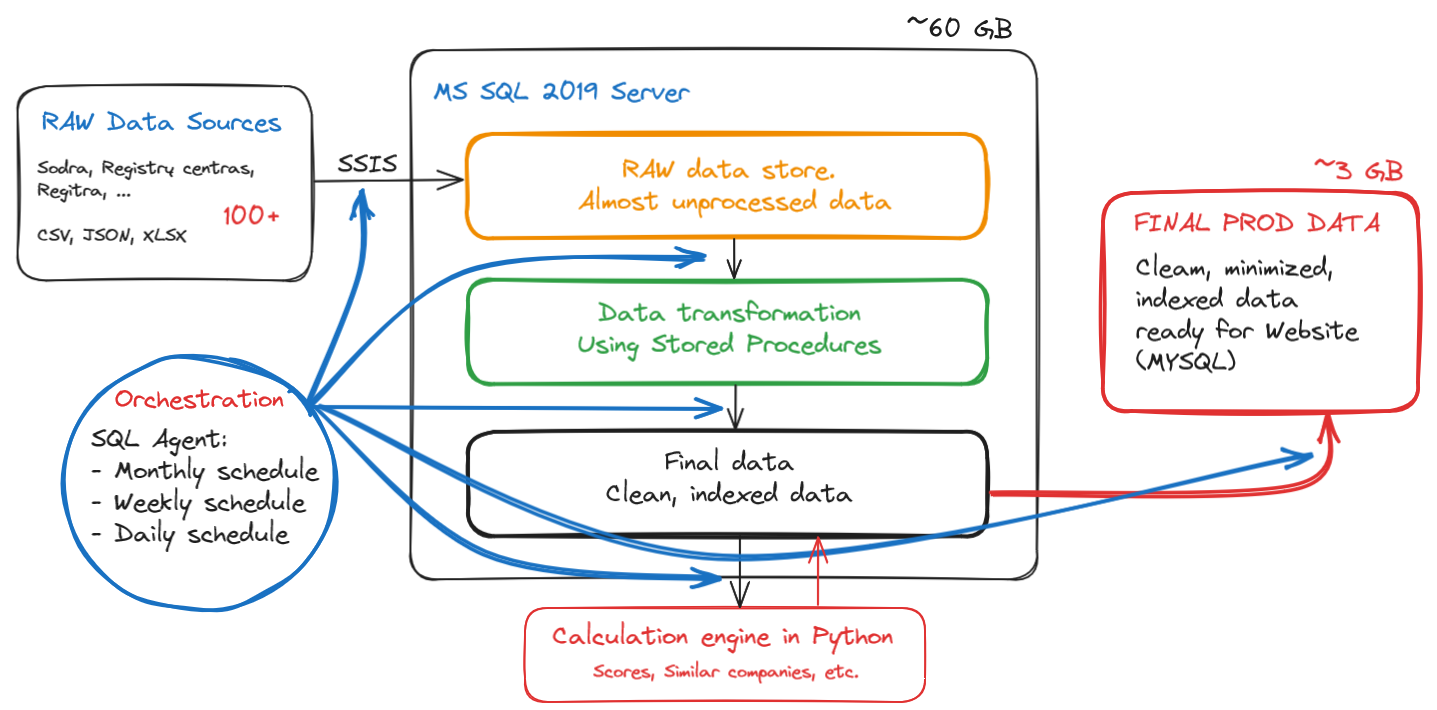
Viskas veikia gan greitai ir stabiliai. Dienos ETL procesas trunka ~30min. Mėnesio ~2 val. Dar yra potencialo optimizavimui.
Dabar beveik visos lentos pilnai reloadinamos, nors duomenų keičiasi nedaug. Tas apsunkina snapshot’ų kūrimą, tai planas netolimai ateičiai optimizuoti, kad krautųsi per deltas ir įjungti snapshot’inimą.
Nauda
Akivaizdi nauda man – sutaupytos 3val per mėnesį. Nauda naudotojams – visad naujausi įmonių duomenys. Bet didžiausia nauda – Scoris ateičiai, tai leis toliau scale’inti platformą. Nauja duomenų architektūra įgalino rinkti daug daugiau istorinių duomenų, kurių anksčiau nerinkadavom visai, kas po kiek laiko (sukapus pakankamai duomenų) leis pasiūlyti naujų produktų ir to, ko nei vienas rinkos žaidėjas neturi.